Getting started¶
Note
This guide was last updated in 2017 and may not be current. The best place to start is with the Pandana demo notebook.
Introduction¶
In this case, a picture is worth a thousand words. The image below shows the distance to the 2nd nearest restaurant (rendered by matplotlib). With only a few lines of code, you can grab a network from OpenStreetMap, take the restaurants that users of OpenStreetMap have recorded, and in about half a second of compute time you can get back a Pandas Series of node_ids and computed values of various measures of access to destinations on the street network.
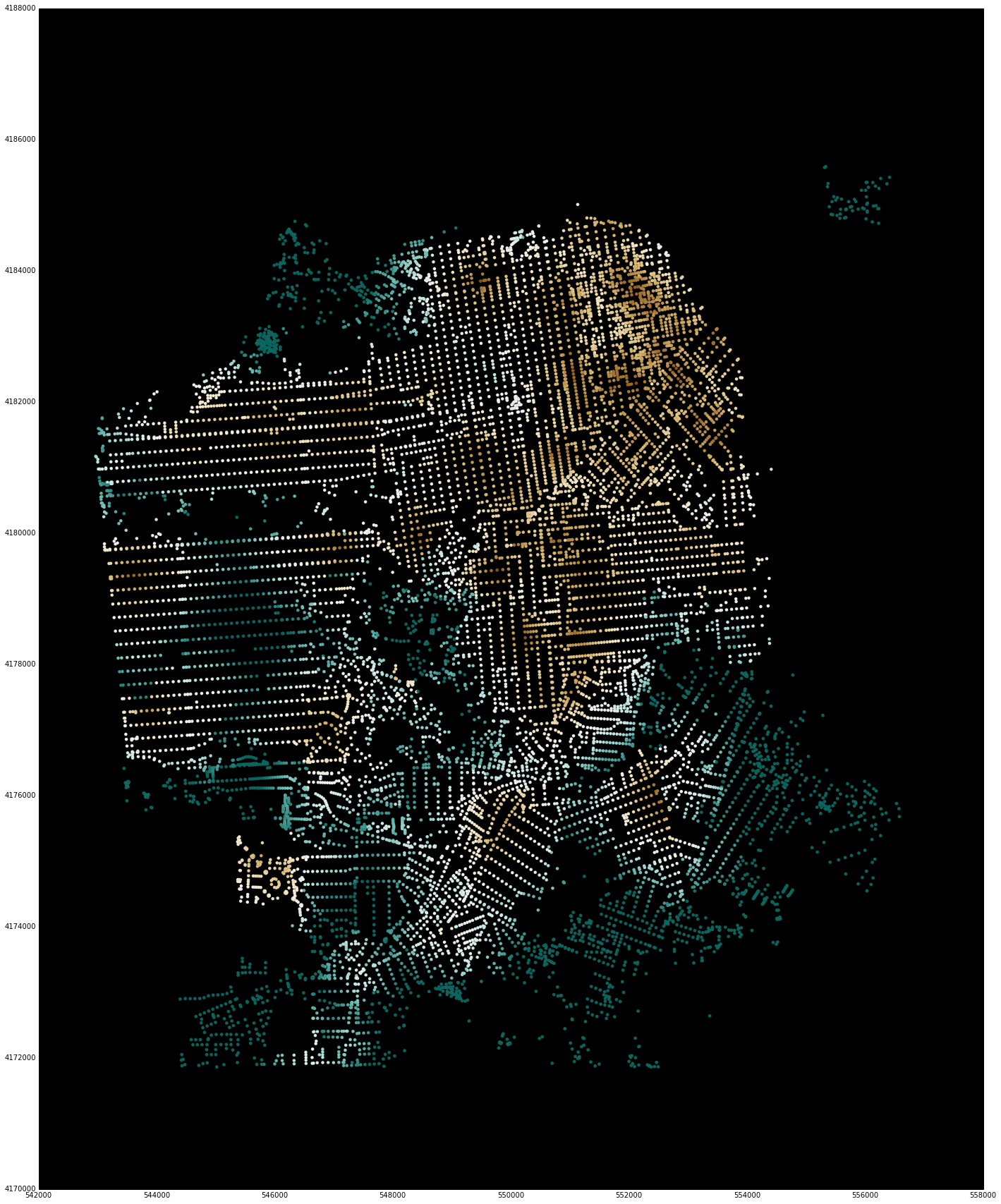
Beyond simple access to destination queries, this library also implements more general aggregations along the street network (or any network). For a given region, this produces hundreds of thousands of overlapping buffer queries (still performed in less than a second) that can be used to characterize the local neighborhood around each street intersection. The result can then be mapped, or assigned to parcel and building records, or used in statistical models as we commonly do with UrbanSim. This is in stark contrast to the arbitrary non-overlapping geographies ubiquitous in GIS. Although there are advantages to the GIS approach, we think network queries are a more accurate representation of how people interact with their environment.
We look forward to creative uses of a general library like this - please let us know when you think you have a great use case by tweeting us at @urbansim or post on the UrbanSim forum.
General workflow¶
Accessibility as defined here is the ability to reach other specified locations in the city, and this framework is first and foremost designed to compute accessibility-to-destination queries of various kinds.
In practice, this framework is a bit more flexible than that. This framework can generally aggregate data along the transportation network in a way that creates a smooth surface over the entire city or region for the variable of interest.
There are a few general steps that are typically followed in measuring a variable using network queries.
Create and preprocess the network
Networks are completely abstract in that they have nodes, edges, and one or more impedances associated with each edge. Impedances can be time or distance or a composite index of some kind, but there is a single number associated with each edge to define the difficulty of getting between the associated nodes. (If you pass multiple impedances for each edge, a different instance of the underlying data structures is created for each network, but these are simply accessed by name for users of the API.) A great use case for multiple impedances is congested travel times that vary by time of day. Pedestrian, auto, and local street networks have all been used in this framework successfully.
Assign a variable to the network
Next, create using Pandas the variable of interest to you. In some cases it’s discrete - like the number of coffee shops, in other cases it’s continuous like the income of households. But you must have observations of some kind tied to x-y coordinates in the city. These x-y coordinates are then assigned a location in the network, usually by doing a nearest neighbor on all the intersections in the network - i.e. each variable is abstracted to exist at one of the nodes of the network.
If this is a problem - for instance a large parcel in the city - it might be necessary to split up the object to many nearby nodes, which is an extra step but fits within the same framework. Other more flexible ways of assigning the variable to the network can be added in the future.
Perform the aggregation
The main use case of Pandana is to perform an aggregation along the network - i.e. a buffer query. The api is designed to perform the aggregations for all nodes in the network at the same time in a multi-threaded fashion (using an underlying C library). Most walking-scale accessibility queries can be performed in well under a second, even for hundreds of thousands of nodes.
To perform an aggregation, pass a maximum distance to aggregate, an aggregation type (sum, mean, stddev), and a decay (flat, linear, exponential). Decays can be applied to the variable so that items further away have less of an impact on the node for which the query is being performed.
Thus the aggregation is performed for the whole network - in the Bay Area this is 226K nodes - and a buffer query up to the horizon distance, typically 500 meters to about 8000 meters, or 45 minutes travel time, is performed for each node.
Find nearest queries are also available, which is technically not an aggregation, but is easily performed with a very similar workflow.
Display, or reuse in other analysis, like UrbanSim statistical models
Once the computation has been performed, a DataFrame is constructed that has the x, y location of nodes and a z value or many z values which is the result of computations in the above workflow. This data is of the form x, y, z and can be displayed with many visualization techniques, and a
plotmethod is available for the network to display directly in matplotlib.The framework can thus be used to map urban outcomes - e.g. access to health care, or urban predictive variables - e.g. average income in the local area, or simply for data exploration. A common use case will be to write to shapefiles and use in further GIS analysis, or to relate to parcels and buildings and use in further analysis within UrbanSim and the Urban Data Science Toolkit. There are many possibilities, and we hope designing a flexible and easy to use engine will serve many use cases.
Reporting bugs¶
Please report any bugs you encounter via GitHub Issues.
Contributing to Pandana¶
If you have improvements or new features you would like to see in Pandana:
Open a feature request via GitHub Issues.
Contribute your code from a fork or branch by using a Pull Request and request a review so it can be considered as an addition to the codebase.
License¶
Pandana is licensed under the AGPL license.